Federated digital archives: interoperability, autonomy, and connectivity via APIs.
Introduction
In the context of digital archives dedicated to art and culture, the need to preserve institutional autonomy while ensuring integrated access to dispersed resources represents a critical challenge. Traditional archives often operate in silos, limiting cross-disciplinary and transnational access to cultural heritage. The concept of archive federation, based on decentralized and interoperable models, emerges as a solution to reconcile independence and collaboration. This document explores the technical and methodological principles for creating a federated network of archives, with a focus on the use of APIs (Application Programming Interfaces) and the preservation of institutional autonomy.
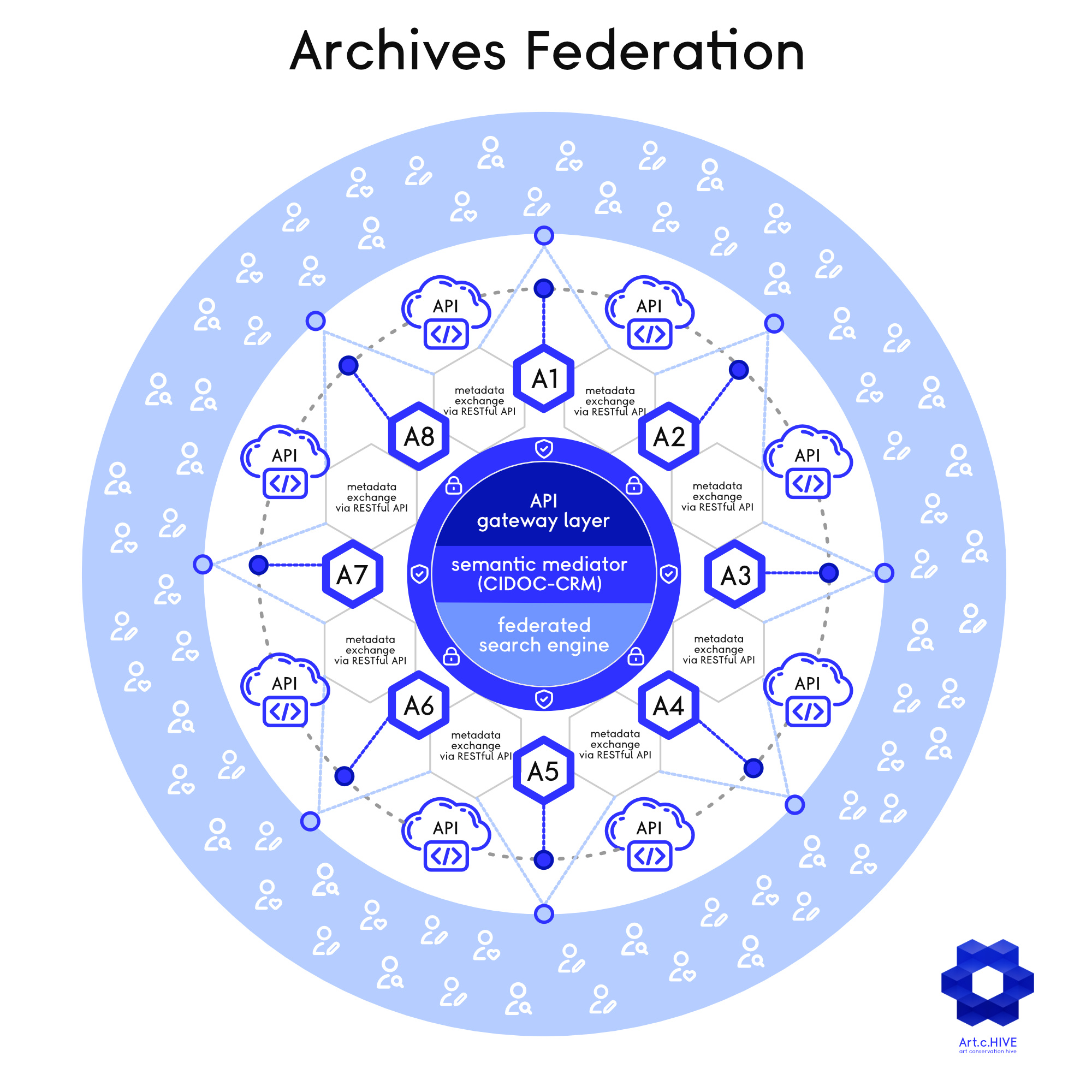
Federated Digital Archives Representation
1. Foundational Concepts of Archive Federation
1.1 Autonomy and Interoperability
A federated system assumes that each archive retains full control over its data, metadata, and access policies. To ensure secure and scalable access management, an authorization framework such as JSON Web Tokens (JWT) can be implemented. JWT provides a lightweight, stateless authentication mechanism that allows secure transmission of user credentials and permissions across distributed archives. Other authorization models, such as OAuth 2.0 and SAML, may also be considered for enhanced access control and identity federation.
Interoperability is achieved through:
- Shared standards: Adoption of common protocols for data description (e.g., XML, JSON-LD) and metadata schemas (e.g., Dublin Core, CIDOC-CRM).
- RESTful APIs: Programmatic interfaces enabling bidirectional communication between archives, allowing data extraction and integration without centralization.
1.2 Decentralized Architecture
Unlike centralized repositories, a federation eliminates single points of control. Each node (e.g., A1, A2, A3, etc.) represents an independent archive, connected to others via APIs. This reduces data monopolization risks and enhances system resilience by ensuring that no single institution or entity has overarching control over the entire network.
2. Technical Implementation
2.1 Role of APIs in Federation
APIs act as the “glue” between archives, enabling:
- Distributed search: Queries executed in parallel across multiple archives, with real-time aggregated results using technologies like Elasticsearch or Apache Solr.
- Metadata exchange: Transfer of contextual information (e.g., provenance, licenses) without moving primary data, ensuring data integrity and reducing storage costs.
- Federated authentication: Mechanisms like OAuth2 to ensure secure, policy-compliant access while maintaining user privacy and data sovereignty.
2.2 Data Models and Semantics
To avoid ambiguity, it is essential to define:
- Common ontologies: Use of controlled vocabularies for concepts like “artwork” or “creator.” While this approach may limit diversity and flexibility, semantic federation allows for local adaptations while maintaining global coherence.
- Dynamic mapping: Tools such as XSLT for XML transformations, also known as bridges, to convert local metadata into federation-compatible formats.
2.3 Scalability and Error Handling
A federated system must include:
- Load balancing: Distributing query loads across nodes to prevent overloads using tools like NGINX or Kubernetes.
- Fallback mechanisms: Ensuring that node failures do not compromise the entire network through redundancy and failover strategies.
- Scalability: The system should accommodate growth in both the number of participating archives and data volume by leveraging cloud-based infrastructure and distributed computing technologies.
3. Benefits and Challenges
3.1 Benefits
- Unified access: Researchers can query global archives simultaneously, reducing duplication of effort and fostering cross-institutional collaboration.
- Respect for local specificity: Each institution retains its management policies and access rights while contributing to a shared knowledge base.
- Collaborative innovation: Integration of AI tools for cross-archive analysis, such as pattern recognition in artworks, enabling new insights and discoveries in cultural heritage research.
3.2 Critical Challenges
- Data consistency: Harmonizing heterogeneous metadata requires ongoing effort and collaboration to align diverse practices.
- Security: Protecting APIs from cyberattacks demands robust encryption, monitoring, and threat detection systems without hindering legitimate access.
- Economic sustainability: Costs of maintaining technical infrastructure can be mitigated through shared funding models and open-source solutions.
4. Case Study: The European Art Archive Federation
A concrete example is the Europeana project, where institutions like the Louvre and Rijksmuseum share metadata via APIs while retaining control over high-resolution images. This model demonstrates how autonomy does not conflict with collaboration by enabling institutions to share data on their own terms. It also illustrates how decentralized systems can scale to hundreds of nodes while maintaining performance and reliability.
5 . Conclusions and Future Directions
Federated digital archives represent an innovative paradigm for cultural heritage management. To fully realize their potential, it is necessary to:
- Strengthen interoperability standards through initiatives like the International Image Interoperability Framework (IIIF).
- Foster partnerships between cultural institutions and IT developers to bridge the gap between technical and domain expertise.
- Explore emerging technologies, such as blockchain for data traceability, to enhance transparency and trust in the federation.
This approach not only preserves institutional identity but transforms archives from static entities into dynamic nodes of a global cultural network, empowering users to explore and connect cultural heritage in unprecedented ways.
