The importance of vector embedding creation for semantic search.
Introduction
Semantic search is a transformative technology that goes beyond traditional keyword matching by understanding the intent and context of a query. At the core of semantic search is vector embedding, a process that converts various media types – text, images, audio, and video – into high-dimensional numerical representations. These embeddings capture the semantic meaning of the content, enabling more accurate and intuitive search results. This comprehensive text will explore the importance of vector embedding creation across different media types, discuss specific models and challenges, and conclude with a review of common algorithms used for semantic search once the data is vectorized.
Text vector embedding
Key Concepts
Text vectorization is essential for converting unstructured text data into machine-readable formats. By capturing the context and relationships between words, phrases, and sentences, vector embeddings enable powerful semantic search capabilities.
Models for Text Embedding
- Word-Level Models:
- Word2Vec, GloVe: Capture the relationship between words based on their co-occurrence in a corpus.
- Limitation: These models fail to capture contextual meaning.
- Contextual Models:
- BERT, RoBERTa, Sentence Transformers: Generate embeddings that consider the surrounding context of each word, making them highly effective for semantic search.
Challenges in Text Vectorization
Preprocessing: Requires removing stopwords, stemming/lemmatization, and handling noisy or unstructured data.
Handling Large Datasets: Large corpora require significant computational resources to generate embeddings.
Data Storage
Text embeddings are typically stored in vector databases (e.g., FAISS, Pinecone) for efficient retrieval.
Image vector embedding
Key Concepts
Images are inherently unstructured and require vectorization to enable semantic search. Embeddings capture visual features like color, texture, and object shapes.
Models for Image Embedding
- CNN-Based Models:
- ResNet, EfficientNet: Extract spatial features of images.
- Specialized models like VGGFace for face recognition.
- Multimodal Models:
- CLIP: Aligns image embeddings with textual descriptions, enabling cross-modal search (e.g., text-to-image retrieval).
Challenges in Image Vectorization
Preprocessing: Requires resizing, normalizing, and sometimes augmenting images.
Domain-Specific Embedding: Face recognition, object detection, and other specific tasks need fine-tuned models.
Data Storage
Image embeddings are stored in high-performance vector databases. Metadata such as labels or categories may also be stored for indexing and filtering.
Audio vector embedding
Key Concepts
Audio embeddings are used for tasks such as voice recognition, music search, and sound classification. Semantic understanding of audio requires capturing both temporal and frequency information.
Models for Audio Embedding
- Voice and Speech:
- Wav2Vec, OpenL3: Generate embeddings for speech and speaker recognition.
- Voice-to-text conversion with models like DeepSpeech can also be used to perform text-based semantic search on audio.
- Music and Sound:
- Models like MusicNN and OpenL3 can embed musical features.
- For more granular search, embeddings can be created separately for vocals and instruments using MIDI recognition or source separation.
Challenges in Audio Vectorization
Noise Removal: Requires preprocessing to eliminate background noise.
Temporal Dynamics: Capturing long-range temporal dependencies in audio data is computationally expensive.
Data Storage
Audio embeddings are stored in vector databases alongside metadata (e.g., speaker ID, language, or genre) to facilitate advanced filtering.
Video vector embedding
Key Concepts
Videos are a combination of spatial (frames) and temporal (motion) information, making their embedding process complex. Vector embeddings enable tasks such as scene recognition, action detection, and multimodal search.
Models for Video Embedding
- Spatiotemporal Models:
- C3D, I3D: Capture both spatial and temporal features.
- SlowFast Networks: Separate pathways for slow and fast motion analysis.
- Face and Object Detection:
- Models like YOLO or Faster R-CNN can detect and embed objects or faces within videos for specific searches.
Challenges in Video Vectorization
Preprocessing: Requires frame extraction, resizing, and sometimes object or face detection.
High Dimensionality: Videos generate large amounts of data, requiring efficient storage and retrieval solutions.
Data Storage
Video embeddings are often indexed in vector databases, with temporal metadata (timestamps, frame IDs) for precise retrieval.
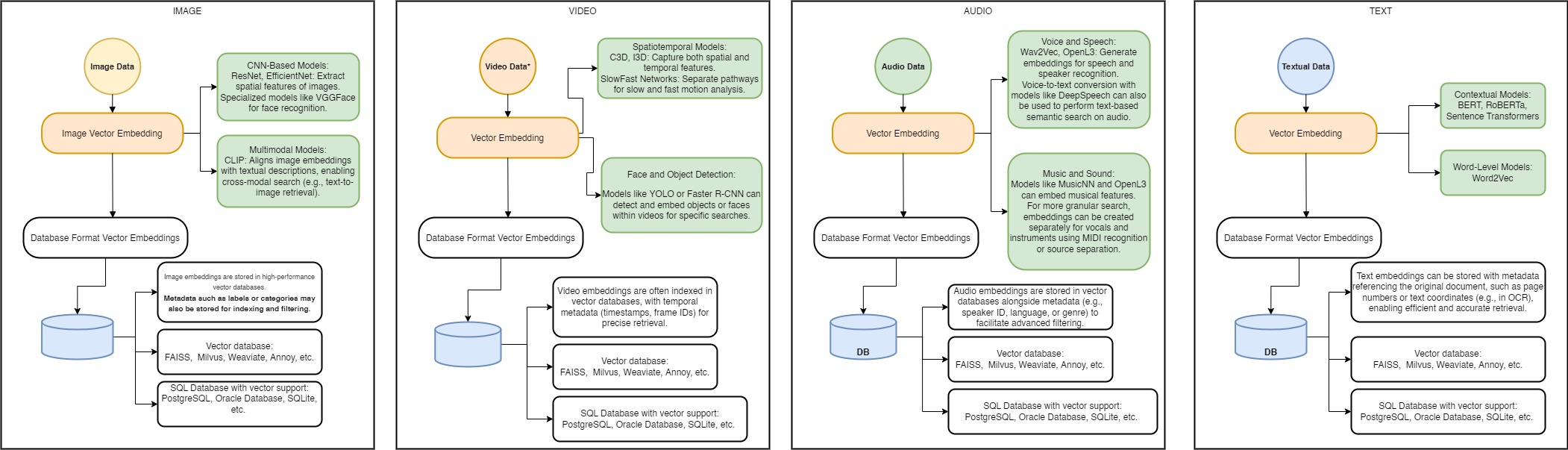
Schema of image, video, audio and text vector embeddings.
Common algorithms for semantic search using vectors
Once embeddings are created and stored, semantic search relies on algorithms to compute the similarity between a query and the stored data. Here are the most common algorithms:
- Cosine Similarity
- Measures the cosine of the angle between two vectors.
- Common for text and image embeddings, as it captures relative similarity regardless of vector magnitude.
- Euclidean Distance
- Computes the straight-line distance between two vectors.
- Suitable for spatial data but less effective for high-dimensional embeddings.
- Dot Product
- Measures the projection of one vector onto another.
- Used in models like CLIP to score similarity between text and image embeddings.
- Approximate Nearest Neighbors (ANN)
- Efficiently retrieves vectors closest to a query in high-dimensional space.
- Libraries: FAISS, Annoy, HNSW (Hierarchical Navigable Small World).
- K-Nearest Neighbors (KNN)
- Identifies the K closest vectors to the query vector.
- Useful for classification and clustering tasks in semantic search.
Conclusion
Vector embedding creation is fundamental to semantic search, enabling machines to understand and retrieve relevant information across text, images, audio, and video. Each media type has unique challenges and requires specialized models for effective embedding. Once data is vectorized and stored, advanced similarity algorithms power the search process, unlocking highly accurate and intuitive retrieval experiences. As semantic search continues to evolve, the importance of embedding creation and optimization will only grow.
